Modèles prédictifs et AutoML : Quelle solution d'Intelligence Artificielle choisir ?
- DataGenius

- 10 mars 2020
- 10 min de lecture
Dernière mise à jour : 4 nov. 2020

Version originale en anglais : Medium
Cet article vous est proposé dans le cadre de notre offre AI-Compare. Nous référençons sur notre plateforme AI-Compare un grand nombre de solutions d'intelligence artificielle (IA) et vous permettons de les tester directement sur notre plateforme ou notre API.
Si vous êtes un fournisseur de solutions d'IA (reconnaissance d'objets, traduction automatique, extraction de mots-clés, speech to text, etc.) que vous souhaitez l'intégrer à AI-Compare ou que vous souhaitez simplement en savoir plus sur notre solution, contactez-nous à l'adresse suivante : contact@ai-compare.com
Bien avant l’apparition de l’expression “Intelligence artificielle”, on utilisait déjà les mathématiques pour analyser des données numériques. De nombreuses entreprises se sont intéressées à l’analyse de données dans une optique de prédiction et d’optimisation. Des méthodes statistiques comme la régression linéaire sont utilisées depuis bien longtemps et dans de nombreux domaines.
Cependant , l'essor de l’intelligence artificielle et plus précisément du Machine Learning, a démocratisé l’utilisation de ces méthodes statistiques afin de former des algorithmes d’apprentissage permettant des prédictions précises et automatisées.

Régression :
Les modèles sont construits par exemple sur la base d’une régression pour créer un modèle permettant la prédiction numérique (par exemple : chiffres de ventes, température, nombre de personnes attendues à un événement, etc.). Ces modèles s’appuient sur une base de données d’entrées qui peut être :
des caractéristiques,
des données historiques (sur plusieurs années),
une donnée de sortie correspondant à la variable que l’on souhaite prédire.
Classification :
Un autre type de modèle de Machine Learning est la classification. Les algorithmes de classification vont permettre de catégoriser un individu en fonction de paramètres d’entrée. On peut citer quelques exemples :
prédiction de la race d’un chien en fonction de caractéristiques,
prédiction de la validité ou non d’une demande de crédit,
prédiction de la météo (soleil, nuageux ou pluie),
prédiction de l’état de fonctionnement de machines, etc.
Ainsi, l’utilisation du Machine Learning (classification et régression notamment) s’est démocratisée dans quasiment tous les domaines : business, météo, finance, commerce, marketing, industrie, santé, etc. Certaines entreprises axent fortement leurs stratégies de vente et de gestion sur des algorithmes de Machine Learning.
AutoML :
Le succès du Machine Learning a engendré une recrudescence de data scientists : des experts de l’intelligence artificielle, capable à la fois d’élaborer des modèles mathématiques complexes, et de développer ces modèles afin de les implémenter.
Depuis quelques temps, de nombreux fournisseurs d’IA ont compris que l’expertise nécessaire pour l’utilisation du Machine Learning était un frein à son expansion au sein des entreprises. C’est ainsi qu’est apparu l’Automated Machine Learning (AutoML), destiné à rendre accessible le Machine Learning au plus grand nombre, et notamment les développeurs n’ayant pas de notions en mathématiques.
L’AutoML permet l’assistance et l’automatisation de nombreuses étapes du processus de création d’un modèle de Machine Learning :
Préparation des données (missing values, doublons, normalisation)
Extraction des labels (caractéristiques)
Sélection des labels
Choix de l’algorithme et des paramètres d’optimisation
L’AutoML présente ainsi l’avantage pour une entreprise de se passer de l’expertise d’un data scientist ou d’un prestataire en data science : cela induit donc une réduction drastique du coût du projet. De plus, la question de mise en production est simplifiée par le fait que les fournisseurs de solutions d’AutoML assurent l'hébergement du modèle, et le stockage des données.
La contrepartie de l’utilisation de l’AutoML est le flou autour de l’algorithme utilisé. On a un effet “boîte noire” (black box), c’est-à-dire que l’utilisateur dispose de très peu d’informations sur l’algorithme détaillé et donc sur l’explication des prédictions.
Evidemment, l’usage de l’AutoML n’est pas recommandé pour tous les projets. L’AutoML présente des défauts qui contraignent à utiliser un algorithme sur mesure :

À noter que l’AutoML n’est pas un outil magique non plus. Un des travail du data scientist, bien que dissocié des mathématiques et du développement informatique, est le rassemblement et la mise en forme des données. Ce travail fastidieux ne pourra être qu'en grande partie manuel et demande une expertise métier (dépendant du domaine d’application) que ne pourra pas assurer l’AutoML.
Concernant la tarification, tous les fournisseurs propose un pricing similaire :
un paiement pour l'entraînement du modèle
un paiement pour le déploiement du modèle selon : la quantité de données et/ou le nombre de cœurs sollicités
Fournisseurs :
Lors de notre étude sur l’AutoML, nous nous sommes projetés dans le rôle d'une entreprise qui souhaite utiliser le Machine Learning pour répondre à des problématiques de prévision de ventes, et de classification client. Nous incarnons une entreprise ne disposant pas d'un expert en IA, souhaitant obtenir un haut niveau de performance à moindre coût, et sans recourir à un prestataire de services.
La première question qui nous vient à l'esprit est donc : "Quel fournisseur choisir ?". Nous avons donc choisi 5 fournisseurs de solutions d’AutoML :
Google Cloud AutoML Tables : https://cloud.google.com/automl-tables
Amazon AWS Machine Learning : https://aws.amazon.com/fr/machine-learning
Microsoft Automated Machine Learning : https://azure.microsoft.com/en-us/services/machine-learning/automatedml/
IBM AutoAI : https://www.ibm.com/cloud/watson-studio/autoai
BigML OptiML : https://bigml.com/whatsnew/optiml
Nous avons testé les 4 solutions des plus gros fournisseurs d’IA du marché, et nous avons également souhaité tester une solution d’un plus petit fournisseur : BigML Opti ML.
Cas d’usage :
Afin d'avoir une vision claire du marché et des différents fournisseurs, nous avons donc comparé ces 5 solutions sur deux projets différents. Un projet de classification et un projet de régression avec d’autres différences significatives : taille de la base de données, nombre d’inputs, domaine. Nous allons donc réalisé ces deux projets pour analyser les résultats des cinq fournisseurs respectivement sur les deux projets.
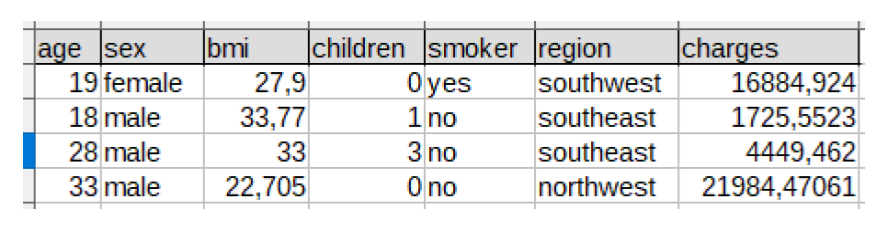
Le premier projet consiste à prédire la charge financière que va représenter une personne pour une compagnie d’assurance. Incarnant une entreprise d’assurance, l’objectif est d’estimer le coût de chaque profil de personne en fonction de paramètres / caractéristiques : âge, sexe, IMC, nombre d’enfants, fumeur / non fumeur, région. Nous disposons pour cela d’une base de données de 1339 individus composés des inputs mentionnées précédemment et de l’output : charge financière.
Le second projet vise à prédire si un crédit doit être accepté ou non. On se place pour ce cas d’usage dans la position d’une banque, souhaitant développer un modèle automatique de validation ou invalidation des demandes de crédit. L’objectif est de prédire oui / non pour chaque demande de crédit en fonction des paramètres suivants : âge, profession, situation maritale, domaine d’étude, crédit en défaut, solde annuel moyen, prêt au logement, prêt personnel, type de contact, dernier mois de contact de l’année, durée du dernier contact, nombre de contacts effectués pendant cette campagne et pour ce client, nombre de jours qui se sont écoulés depuis la dernière fois que le client a été contacté dans le cadre d'une campagne précédente, nombre de contacts effectués avant cette campagne et pour ce client, résultat de la campagne de marketing précédente.
Comme pour le premier projet, le dataset présente des données catégorielles et des données numériques. Nous disposons donc d’une base de données de 45 212 individus composés des inputs mentionnées précédemment et de l’output : réponse (oui / non).

Avantages et inconvénients des solutions :
Après avoir appréhendé et pris en main les 5 solutions sur deux cas d'utilisation distincts, certaines différences sont apparues entre les solutions dans l'approche et dans l'utilisation.
Tout d’abord pour accéder au service de chaque provider, le processus diffère. Chez Google, il suffit de se connecter à la console et de se rendre sur le service AutoML Tables et de créer un ensemble de données. De même, il suffira de se connecter à la console AWS et d’aller sur Amazon Machine Learning. Les cas Microsoft et IBM sont plus complexes.
Pour Microsoft, il faut se connecter sur le portail Azure, puis créer une nouvelle ressource Machine Learning. Il faut ensuite se connecter sur Microsoft Azure Machine Learning Studio et créer une nouvelle exécution. Le processus n’est pas très intuitif, et plutôt laborieux.
L’accès à l’AutoML chez IBM n’est pas simple non plus : se connecter à Watson Studio, puis créer un nouveau projet, et associer à ce projet l’AutoAI experiment, puis choisir l’instance de Machine Learning (et la machine associée). L’étape ne paraît pas complexe dans l’explication, elle est pourtant loin d’être intuitive une fois sur la plateforme.
L’utilisation de BigML ne présente aucune difficulté, il suffit de se connecter à son dashboard pour pouvoir directement construire son modèle.
Vient ensuite l’étape de l’importation de la base de données. Chez Google et Amazon, il faut d’abord stocker le fichier .csv dans un bucket dans leur service de Cloud. Ensuite il peut être importé facilement, après la création d’un datasource pour Amazon.
Avec Microsoft, il faut créer un jeu de données : importer un fichier .csv, visualiser le jeu de données importé et modifier potentiellement le type de données. Pour IBM, il faut ajouter un “asset” dans le projet, puis importer cet asset dans AutoAI experiment. L’interface de BigML propose simplement d’importer une source de données (notre fichier .csv) puis de la configurer (configurer les colonnes), puis de l’importer en tant que dataset.
Il faudra ensuite, peu importe le fournisseur, choisir la donnée cible, c’est-à-dire la colonne que l’on souhaite prédire. On en vient enfin à l’étape clé du processus : la création et le paramétrage de l'entraînement et du modèle. Chaque fournisseur restreint ou autorise certains éléments de contrôle sur la réalisation du modèle, à des degrés différents :
Google AutoML Tables laisse le choix à l’utilisateur, soit d’utiliser la répartition automatique du split Training / Test, soit de choisir lui-même cette répartition. Ensuite l’utilisateur a des choix différents à faire selon le type d’algorithme mis en jeu :
Pour une régression, l’utilisateur devra choisir le paramètre d’optimisation sur lequel son modèle sera axé : RMSE (capturer les valeurs les plus extrêmes avec précision), EAM (les valeurs extrêmes auront moins d’incidence sur le modèle), RMSLE (pénaliser l’erreur sur la taille relative plutôt que sur la valeur absolue : utile pour des valeurs prédites et réelles très élevées)
Pour une classification, l’utilisateur pourra également choisir le paramètre d’optimisation du modèle : AUC ROC (distinguer les classes), Perte logistique (maintenir un niveau de précision élevé des probabilités de prédiction), AUC de la courbe précision / rappel (maximiser la courbe précision / rappel pour la classe minoritaire), précision (proportion correcte des identifications positives), rappel (proportion correctement identifiée des résultats positifs réels).
Google offre la possibilité d’influer sur ses paramètres, mais l’utilisateur peut utiliser les choix par défaut. Pour la classification comme pour la régression, il est nécessaire de définir le nombre de nœuds d'entraînement, ainsi qu’il est possible d’exclure des colonnes de la base de données.
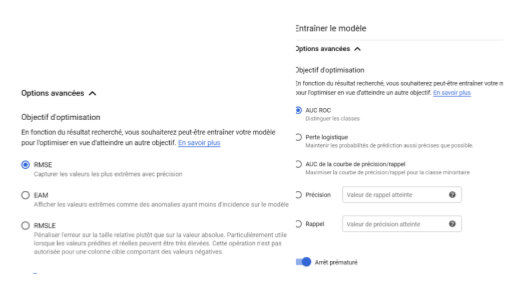
AWS Machine Learning offre à l’utilisateur a deux possibilités :
Default : si l’utilisateur choisit cette option, alors il aura un bilan de l'entraînement par défaut, des paramètres d'entraînement par défaut, une répartition training / test du dataset à 70% / 30%
Custom : l’utilisateur va pouvoir choisir la taille maximale du modèle (correspondant au nombre de patterns créés par le modèle), le nombre d’itérations (le nombre de fois où Amazon ML va analyser les données pour trouver des patterns), le type de régularisation (pour éviter l’overfitting). L’utilisateur va également pouvoir choisir un split training / test automatique (aléatoire ou sur les 30% derniers du dataset) ou un dataset de test importé manuellement.
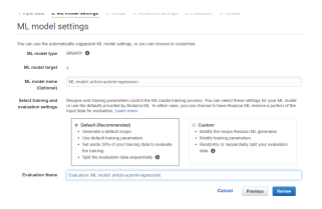
Microsoft Azure Machine Learning utilise les algorithmes de Scikit Learn, il créé donc de nombreux modèles avec les différents algorithmes pour trouver celui qui donne les meilleurs résultats. Cette solution permet à l’utilisateur de choisir directement le type d’algorithme correspondant au dataset et à la problématique : classification, régression ou séries temporelles (prévision de séries chronologiques).
Il est possible de choisir la métrique principale pour optimiser le modèle, de bloquer certains algorithmes, choisir la durée d'entraînement, le nombre d’itérations simultanées (modèles simultanés). L’utilisateur peut également exclure des variables ou encore choisir le type de validation (Monte-Carlo, cross validation, train validation split).
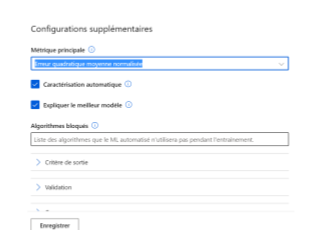
IBM Watson AutoAI Experiment offre à l’utilisateur un paramétrage assez proche de celui de Microsoft. Un choix de la répartition train / test est possible; tout comme l’exclusion de variables. Pour la prédiction, l’utilisateur peut choisir entre : régression, classification binaire et classification multiclasse. Il faut ajouter à cela la possibilité de choisir la métrique d’optimisation et exclure des algorithmes.
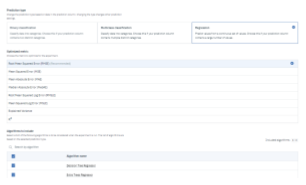
BigML fonctionne très simplement mais offre très peu de contrôle sur le paramétrage du modèle. L’utilisateur peut créer une répartition 80%/20% train / test. Il est possible de choisir la métrique d’optimisation du modèle, d’attribuer des poids aux différentes classes et également de choisir le pourcentage d’échantillons du dataset à utiliser pour la construction du modèle.
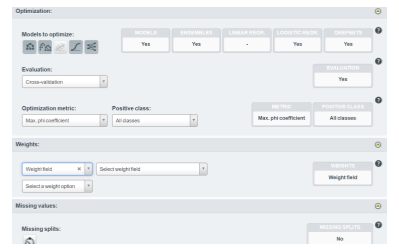
Ainsi, IBM et Microsoft offrent un large choix de paramètres sur lesquels l’utilisateur peut influer. Google propose légèrement moins de paramètres mais ceux-ci sont bien détaillés et très accessibles. BigML propose peu d’options paramétrables, tandis qu’Amazon propose une accessibilité à des paramètres différents : peu abordables pour des utilisateurs novices qui n’auront pas les notions ni l’expérience nécessaire pour capitaliser sur ces paramètres.
Évaluation du modèle :
L’évaluation du modèle permet de déterminer la fiabilité du modèle selon :
des critères de performances représentatifs de la qualité générale du modèle,
des critères plus spécifiques selon le besoin de l’utilisateur.
Certaines métriques sont communes à tous les fournisseurs : le RMSE pour la régression et le AUC ROC pour la classification. Ce sont ces métriques que nous allons considérer pour comparer les différentes solutions.
Le RMSE est Root Mean Squared Error soit l'erreur quadratique moyenne (RMSE). C’est l'écart-type des résidus (erreurs de prédiction). Les résidus sont une mesure de l'éloignement des points de données de la ligne de régression. La formule est :

Avec :
f = prévisions (valeurs attendues ou résultats inconnus),
o = valeurs observées (résultats connus)
La courbe AUC - ROC est une mesure de performance pour les problèmes de classification à différents seuils. ROC est une courbe de probabilité et AUC représente le degré ou la mesure de séparabilité. La métrique utilisée est l’aire sous la courbe :
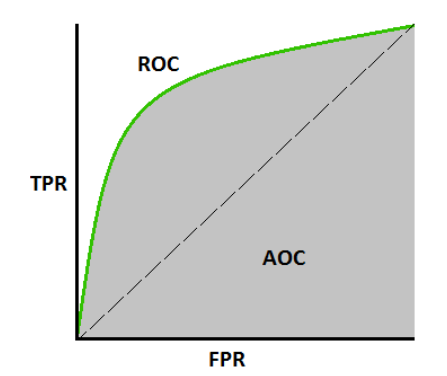
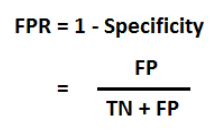
Avec :

Google, Microsoft et IBM fournissent une évaluation très complète avec de très nombreuses métriques et une matrice de confusion pour la classification. BigML fournit moins de métriques de résultats mais cela reste suffisant. En revanche, Amazon affiche une seule métrique concrète : RMSE pour la régression et AUC ROC pour la classification. Certes, ce sont les métriques les plus standards, cependant elles peuvent ne pas être suffisantes pour réellement évaluer la qualité du modèle en fonction de la problématique.
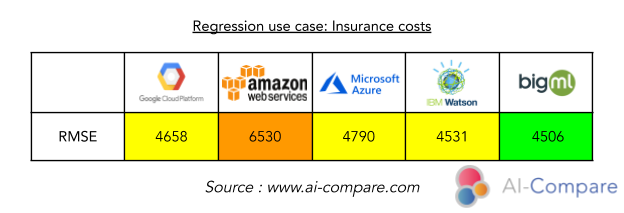
Plus le RMSE est faible, plus le modèle est performant. Ceci donne ce classement : BigML > IBM Watson > Google Cloud > Microsoft Azure > Amazon Web Services
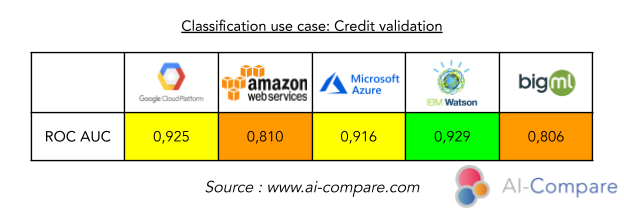
Plus le AUC ROC (aire sous la courbe) est proche de 1, plus le modèle est performant. Ce qui donne ici ce classement : IBM Watson > Google Cloud > Microsoft Azure > Amazon Web Services > BigML.
Ainsi, pour le projet de prédiction des coûts en assurance, on privilégiera plutôt BigML. A contrario, pour le projet de prédiction de l’acceptation des crédits, BigML affiche de faibles performances et on privilégiera davantage IBM et Google pour ce projet.
Conclusion :
L’AutoML s’adresse davantage aux développeurs qu’aux data scientists, mais ces solutions présentent tout de même de réels attributs.
Pour chaque projet, chaque cas d'utilisation, une analyse est nécessaire afin d'évaluer les performances et les conditions d’utilisation de chaque solution. Il a été observé au cours de cette étude que chaque cas est spécifique et que nous ne pouvons pas être certains du choix de la solution avant d'en avoir testé plusieurs disponibles sur le marché. Certaines solutions peuvent apporter des résultats très faibles, d'autres excellents, et cette logique peut totalement changer pour un autre cas d'utilisation. En outre, selon le projet, la priorité sera donnée aux coûts, aux résultats, aux temps de calcul et au nombre de requêtes par seconde, ou à la facilité d'utilisation et de manipulation. Ce sont tous ces critères qui peuvent avoir un impact sur la décision, et qui permettent de choisir la solution qui convient le mieux au projet, la solution la plus pertinente.
C'est sur cette base que notre offre AI-Compare entre en jeu. Grâce à notre expertise approfondie dans l'utilisation de ces différentes solutions d'Intelligence Artificielle, nous sommes en mesure de vous fournir la recommandation la plus adaptée à votre problème. N'hésitez pas à nous contacter pour nous décrire votre besoin : ici.

AI-Compare est une solution SaaS fournissant une API connectée aux grands (AWS, Google Cloud, Microsoft, etc.) et aux petits (Cloudmersive, OCR.Space, etc.) fournisseurs d'intelligence artificielle. Notre solution permet aux utilisateurs de comparer les performances de ces fournisseurs en fonction de leurs données et de les utiliser directement via notre API, offrant ainsi une grande flexibilité et facilitant le changement de fournisseur et l'optimisation des performances : lien d'inscription
Nous proposons également des prestations de conseil en Intelligence Artificielle pour aider nos clients à choisir les meilleures solutions en fonction de leurs besoins et de leurs données : contactez-nous



Commentaires